This is my second post while exploring Nvidia DIGITS. My original goal was to follow instructions available at https://github.com/NVIDIA/DIGITS/tree/master/examples/object-detection. But, I will show that this is not really possible on an AWS g2.2xlarge machine.
Go to http://www.cvlibs.net/datasets/kitti/eval_object.php and download these files:
- Left color images of object data set | `data_object_image_2.zip` | 12GB
- Training labels of object data set | `data_object_label_2.zip` | 5MB
- Object development kit | `devkit_object.zip` | 1MB
Now, download https://github.com/NVIDIA/DIGITS to your desktop and place all three zip files inside of the DIGITS/examples/object-detection/ folder. You now have to sftp this entire modified DIGITs repository to your AWS server. This took me approximately seven hours, and I do not know a work-around for this long step.
Now, in your aws server, cd into the folder DIGITS/examples/object-detection/ and run 'python prepare_kitti_data.py'.
Extracting zipfiles ...
Unzipping data_object_label_2.zip ...
Unzipping data_object_image_2.zip ...
Unzipping devkit_object.zip ...
Calculating image to video mapping ...
Splitting images by video ...
Creating train/val split ...
Done.
Now, you will have folders like DIGITS/examples/object-detection/kitti-data/train/images and DIGITS/examples/object-detection/kitti-data/train/labels. Remember these paths, because you'll need them in the DIGITS UI.
A label is a .txt file of the following form, indicating the object and the location of a box surrounding the object.
Car 0.00 0 -1.59 523.41 194.53 550.65 219.39 1.44 1.66 4.53 -4.82 2.90 47.02 -1.69
Van 0.00 0 -1.68 572.15 185.81 606.45 219.24 2.02 1.70 4.60 -1.42 2.89 47.11 -1.71
Tram 0.00 2 1.27 387.26 166.06 473.51 213.36 3.46 2.57 14.66 -15.22 3.07 59.75 1.02
DontCare -1 -1 -10 176.23 181.27 229.40 218.81 -1 -1 -1 -1000 -1000 -1000 -10
DontCare -1 -1 -10 280.40 180.23 305.44 204.23 -1 -1 -1 -1000 -1000 -1000 -10
DontCare -1 -1 -10 473.10 177.10 526.27 210.47 -1 -1 -1 -1000 -1000 -1000 -10
DontCare -1 -1 -10 638.42 180.23 680.62 197.42 -1 -1 -1 -1000 -1000 -1000 -10
DontCare -1 -1 -10 1014.10 194.46 1033.60 213.63 -1 -1 -1 -1000 -1000 -1000 -10
DontCare -1 -1 -10 685.12 185.18 720.99 196.91 -1 -1 -1 -1000 -1000 -1000 -10
DontCare -1 -1 -10 728.15 185.64 761.31 198.77 -1 -1 -1 -1000 -1000 -1000 -10
DontCare -1 -1 -10 767.51 186.02 806.60 199.96 -1 -1 -1 -1000 -1000 -1000 -10
DontCare -1 -1 -10 834.96 190.62 867.62 203.53 -1 -1 -1 -1000 -1000 -1000 -10
DontCare -1 -1 -10 940.02 193.50 955.24 208.91 -1 -1 -1 -1000 -1000 -1000 -10
DontCare -1 -1 -10 1053.50 194.11 1083.65 220.00 -1 -1 -1 -1000 -1000 -1000 -10
DontCare -1 -1 -10 1105.00 195.80 1145.53 220.10 -1 -1 -1 -1000 -1000 -1000 -10
DontCare -1 -1 -10 1202.80 191.24 1239.90 220.90 -1 -1 -1 -1000 -1000 -1000 -10
DontCare -1 -1 -10 889.87 187.13 918.06 207.79 -1 -1 -1 -1000 -1000 -1000 -10
DontCare -1 -1 -10 800.19 180.23 843.98 203.19 -1 -1 -1 -1000 -1000 -1000 -10
DontCare -1 -1 -10 955.40 184.40 1009.61 221.94 -1 -1 -1 -1000 -1000 -1000 -10
DontCare -1 -1 -10 1135.60 182.31 1203.35 228.19 -1 -1 -1 -1000 -1000 -1000 -10
Now load the data into DIGTIS. On the DIGITS home page, select the `Datasets` tab then click `New Dataset > Images > Object Detection`:

On the dataset creation page, specify the paths to the image and label folders for each of the training and validation sets. Other fields can be left to their default value. Finally, give your dataset a name and click `Create`:

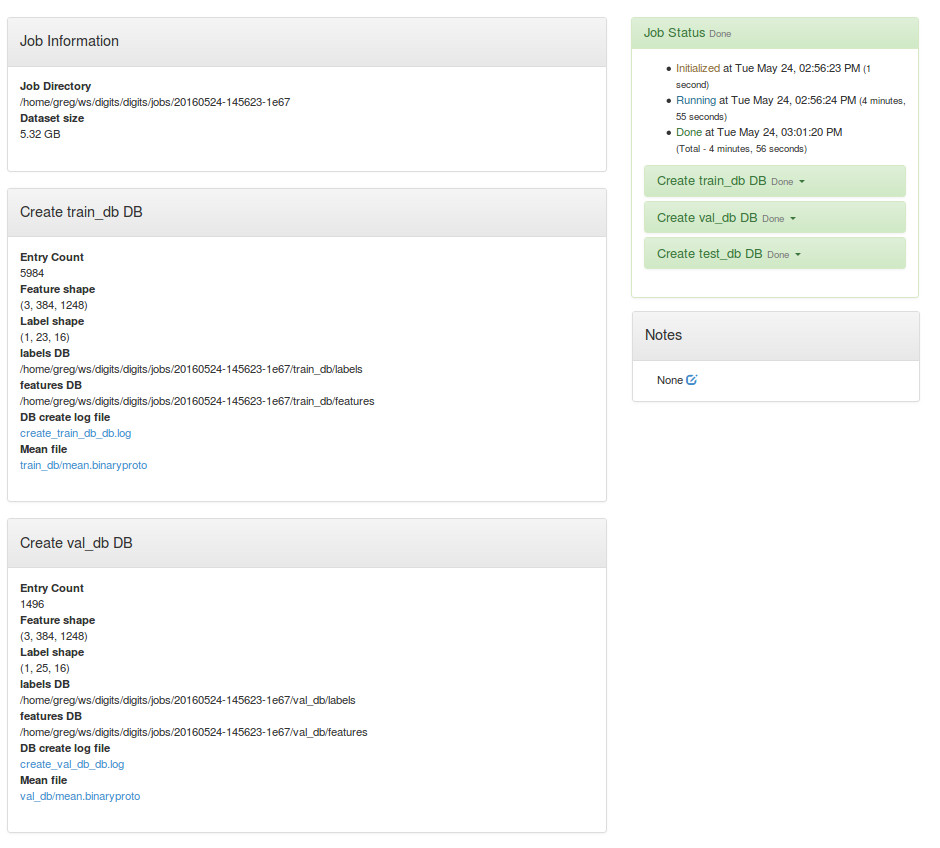
We can review data properties by visiting the dataset page. In our example there are 5984 images in the training set and 1496 images in the validation set:
We will use the DetectNet model. DetectNet is a GoogLeNet-derived network that is specifically tuned for Object Detection. Since DetectNet is derived from GoogLeNet it is recommended we use pre-trained weights from an ImageNet-trained GoogLeNet as this will help speed up training. The model description can be found at https://raw.githubusercontent.com/NVIDIA/caffe/caffe-0.15/examples/kitti/detectnet_network.prototxt and pre-trained weights may be found at https://github.com/BVLC/caffe/tree/rc3/models/bvlc_googlenet. We will need to sftp the model into our AWS machine.
On the DIGITS home page, select the `Models` tab then click `New Model > Images > Object Detection`:

On the model creation page:
- Select the dataset that was created in the previous section.
- Set `Subtract mean` to `None`.
- Set the base learning rate to 0.0001.
- Select the `ADAM` solver.
- Select the `Custom Network` tab.
- Make sure the `Caffe` sub-tab is selected.
- Paste the DetectNet model description in the text area.
- In `Pretrained model(s)` specify the path to the pre-trained GoogLeNet.
Click `Visualize` to review the network topology:
Supposedly, on a 4GB card, you can set the batch size to 2 and the batch accumulation to 5, for an effective batch of 10, and that should fit on your card.
However, when the model started running training is apparently very slow on an AWS g2.2xlarge machine. As you can see, it would have taken me over three days to train this model.

Supposedly, if I let this run for the full 3 days or had access to better GPU's, we would get relatively accurate object detections like the one's displayed below.


That's it for a first run with object detection using Nvidia DIGITS. While this project was not really a success, I did learn a lot while working on it.